





SEO用語解説 - K
構造化データとは?

全日本SEO協会 特別研究員 大谷 将大
作成:2021年10月1日
Google・Yahoo!・BING~と、これまで数々の検索エンジンが世の中に登場してきました。
これらの検索エンジンはいろいろな違いがありますが、「検索結果の画面は、どれもたいして変わらない」そんなイメージを持つネットユーザが多いかもしれません。しかし検索結果の表示は少しずつ変わっています。最大手のGoogleにしても細部が随時進化しているのです。
今回のテーマ「構造化データ」も、検索結果の進歩に関心を持つことで気づける注意点です。「構造化データの活用」ができるようになれば、自社サイトの情報の露出をGoogleの検索結果上で増やすことが可能になります。
構造化データとは何なのか? どんな目的のために使われるデータなのか?

SEOの方法論は、突然変化します。その変化についていくには、ニュースと毎日のようににらめっこしていないとうまくいきません。
といっても、日々の仕事で多忙な中ですべてのニュースをチェックするのは不可能でしょう。とはいえ、Googleの関係者のような一部の専門家が発信するニュースをチェックするくらいなら、何とかなる可能性があります。
たとえば、「サーチ・エンジン・ジャーナル(Search Engine Journal)」ことSEJは、定期購読する価値のあるメディア。この媒体には、Googleのベテラン社員であるゲイリー・イリーズ氏の声明がたまに掲載されます。
そのイリーズ氏が数年前に「Structured Data」のことをネタに、全世界の事業者に向けてアドバイスしてくれたことがありました。
Structured Dataとはそもそも何でしょうか? 日本語に訳すと「構造化データ」となりますが、これはGoogleが抱えている仕組みの一種です。
1 構造化データのアウトライン
では、全日本SEO協会が2020年5月に発売したSEO検定試験3級の公式テキストをご覧ください。
このテキストはこれまで何度も改訂していますが、この版では第6章に「構造化データとは何か」という章を追加しています。

構造化データは、最近いきなり生み出されたものではないのですが、Googleは構造化データをこの数年で非常に推進していることは紛れもない事実です。
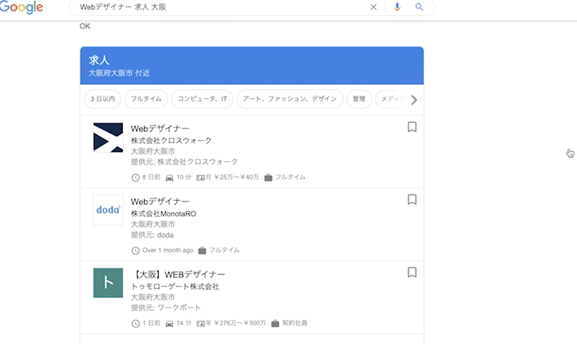
「ウェブデザイナー求人 大阪」 という組み合わせで検索してみましょう。
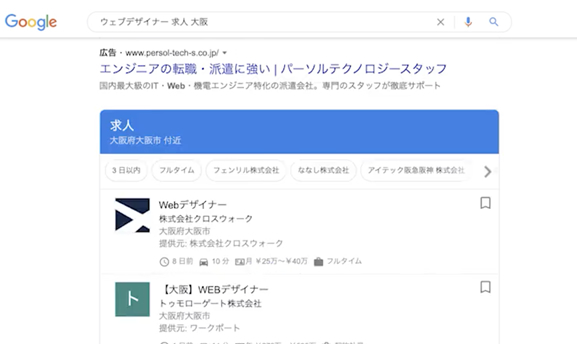
Googleマップのような、特別な枠が出てきますね。これはご覧のように求人欄です。
それでは、「ウェブデザイナー求人」と1語だけで検索するとどうでしょうか?
↓出てきました。
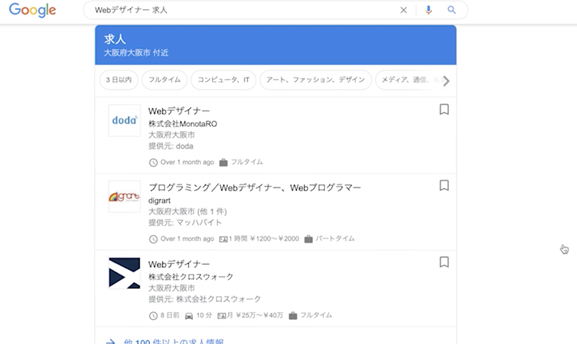
これは、構造化データを実装しているサイトだけの特典です。
それでは、「その他100件」とありますのでこれを試しましょう。
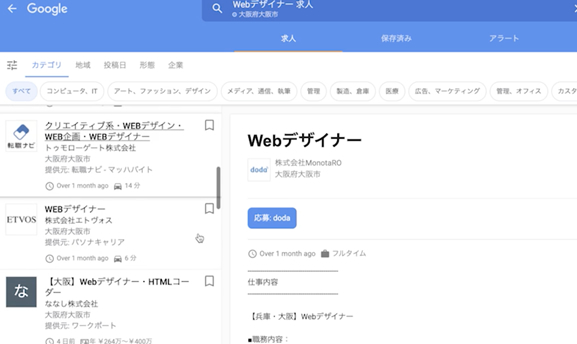
いろいろな会社が構造化データを実装することで、(左側に)このGoogleの特別な求人ポータルサイトに露出することに成功しています。これは構造化データの代表的な用途です。
もう一度見てみますと、Googleの自然検索欄の広告のすぐ下に、求人の構造化データを実装しただけで、こうやって3件の枠に出てくることがわかります。
その下には、通常のオーガニック検索(=自然な検索)の結果が表示されます。
オーガニック検索では、ほかにも自動的に出てくるリンクがあります。検索したときに、平凡な表示内容に混じってQ&Aが出てきたことはないでしょうか?
そのQ&Aでは、質問が4~5件出てきて、下向きの↓をクリックすると回答を読めるようになっています。これを用いると、その上のリンクも自然と目立つことになります。サイトを運営する側にとって得はあっても損はありません。
2 構造化データの存在意義
1.構造化データからブランディング、カスタマージャーニーへ
まとめますとSEOは本来、Google上での検索順位を上げることが常に究極の目的ですが、構造化データによってまた新たなSEOが誕生して、順調に成長している……と捉えるとわかりやすいでしょうか?
この新しいSEOは、検索結果が表示されたときに、他社より露出することが直接の目的。構造化データで他社より目立ち、同時に他社よりもアクセスを増やすことが目的となります。
自社サイトの存在感を高めることはブランド価値を高めることにつながります。ブランドの価値が高まれば、別の日にまた同じユーザがGoogleで検索したときに、自社のサイトを他社のそれよりも真っ先に思い出してくれることでしょう(親近感や信頼感を増幅させることができるのです)。売り上げが伸びるチャンスも増えることでしょう。
これはいわゆる、カスタマージャーニーという今はやりの言葉をほうふつとさせます。カスタマージャーニーとは「ユーザが、企業の商品やサービスを認識してから、申し込み&決済を決断するためのプロセスをたとえた表現」です。長い旅になぞらえて、カスタマージャーニー(旅をするのは、消費者ということです)と表現しているのです。
カスタマージャーニーの最初の一歩は、「認識」「認知」です。英語では「Awareness」という単語が使われます。自社の存在を、消費者が初めて気づいてくれた段階を指しますね。カスタマージャーニーのその次の段階は「比較」でしょう。商品・サービスに関心を持っても、消費者はすぐに飛びつくでしょうか? たいていの場合は、もっといい商品がないか探すことでしょう。他の商品が見つかれば、比較をするはずです。
これらの過程を経てやっと、消費者は購入を決断するわけです。
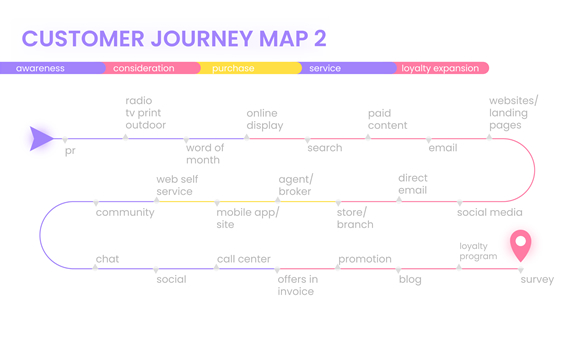

このようなカスタマージャーニーの一連の過程は、ブランドをつくるために適しています。まさにブランディングの王道と言えます。
以上が、構造化データをつくって利用するための動機ですが、ここで誤解してはいけない点があります。それは「構造化データはどんな人たちが何の目的で開発したのか?」という経緯です。
2.構造化データの誕生を振り返ると? 判明する事実とは
構造化データは、本来はGoogleのために開発されたのではありません。SEOのためでもありません。全日本SEO協会のSEO検定3級テキストに書かれていますが、「セマンティックWeb」という目的のためでした。
セマンティックWebとは?
検索エンジンを含めて昔のシステムは、どうやって言葉を認識していたのでしょうか。たとえば「名古屋」という3文字で構成される地名を、昔のシステムはじゅうぶんに認識も理解もできませんでした。少なくとも、「何か3文字の地名がある」くらいの認識がやっとでした。愛知県の中にある名古屋市……という認識はできなかったのです。
この弱点はSEOにもろにつながっていました。「名古屋」というキーワードで上位に入りたい人が、そのページ内に名古屋という文字をたくさん書き込めばよかった時代がありましたが……、これは文字の認識に大きな制限があったからでした。
この点をもっと掘り下げると、統計という仕組みの限界に突き当たります。
あるページに「ディズニーランド」という言葉がいくつも書かれているのに、その代わりに他の言葉がほとんど書かれていなかったら、そのページは「『ディズニーランド』という言葉で検索上位表示させよう」という魂胆があることは見え見え。このように、各ページ内に書かれている各言葉の統計で順位の決定が左右されていたわけです(……ある時期までは)。
しかし「それではいけない」という考え方が持ち上がりました。そこで一部のWeb技術の担い手たちが考え出したのがセマンティックWebという概念だったのです。
このセマンティックWebは、ひとつひとつの言葉に意味を持たせることで、それまでの諸問題を解消させようというシステムでした。(これはGoogleだけに限らず、IBMやオラクルのようなメジャーなデータベースメーカー等も該当するのですが……)「ひとつひとつの言葉の意味を、できるだけシステムに理解・認識させよう」という壮大な計画が実際に立てられてスタートしたのです。それがセマンティック構想の概要です。
このシステムは当然、膨大な時間を必要とします。しかし、時間とともに人間の感覚に近づくことが可能となります。
「ディズニーランド」を、「人々が詰めかけるテーマパーク」であると、その定義を記憶できる……そんな段階を目標とする発想だったのです。
今にして振り返ると、人工知能がすべての産業に応用される時代には非常に適していると評価できます。
ここでやや実務的なことを書きますと、私たちが「東京ディズニーランドの楽しさ」というテーマのWebページを新たにつくったとします。しかし、文章をただ書くだけでは、今のシステムではあまり理解しないでしょう……今のシステムだからこそ、理解できなくなっているともいえます。
そこで代わりに必要となるのは、メタタグのようなものをたくさん書き込むことです。たとえば、場所はどこなのかという定義もそのひとつですね。千葉県浦安市、と忘れずに書かないといけません。ビジネスのタイプにしても、テーマパークであるとかエンターテインメントであるとか、書き込んでおかないといけません。
メタタグの種類も豊富ですが、メタタグはどちらかといえば大雑把です。
Googleのようなシステムに向けて、このページはこういうテーマだということで、メタキーワーズやメタディスクリプションを書き込みますが、大雑把に書いても許されてしまう一面があります。
この点は、構造化データの書き方とは正反対です。構造化データの書き方は事細かな指定でいっぱいですから。「これこれこの行動は、この順番で入れなさい~」、といった具合に、複雑な条件がたくさん待ち構えているのです(プログラミングに近い感覚だととらえるとわかりやすくなるのではないでしょうか)。
構造化データの歴史的な経緯は以上です。それでは、今度は構造化データの分類に移りましょうか。
構造化データは、どのようにして入れればよいのか?
1 構造化データの規格
以下に述べる規格はいずれも、構造化データを記述するために用いられる方式です。
1.マイクロデータ(Microdata)
最初に(仕様)統一された構造化データです。
2.RDFa Lite
「RDFa」という仕様を簡素に変えて使いやすくされた種類です。マイクロデータと記述形式がやや似ています。
3.JSON-LD
これは、構造化データに精通している技術者と話していると頻繁に名前が出てくる規格。需要の高さではダントツです。
JSON-LDが3種類の中でいちばん需要が高い理由は何でしょうか? それはとても単純明快。GoogleがJSON-LDを推奨しているからです。JSON-LDは、どうやらGoogleのシステムにとって、いちばん理解しやすいらしいのです。
これは推論になりますが、JSON-LDはHTMLと分離して記載できるのですがこれは管理面でとてもありがたいメリットです。それも、JSON-LDがGoogleに採用される一因でしょう。
※HTMLは、今では一からベタ打ちするコーダーは少なくなりました(それをやっていると、どんな名人でも時間がかかりすぎてしまいますから当たり前ですが)。最近はオーサリングツールやCMSを使うことがほとんどですが、WordPressのようなCMSでは、今では構造化データを比較的楽に記述できる機能を備えたプラグインがリリースされています。
2 構造化データの具体的な記述方法
ではここで、改めて「構造化データ Google」という言葉でGoogle検索を試みますと……
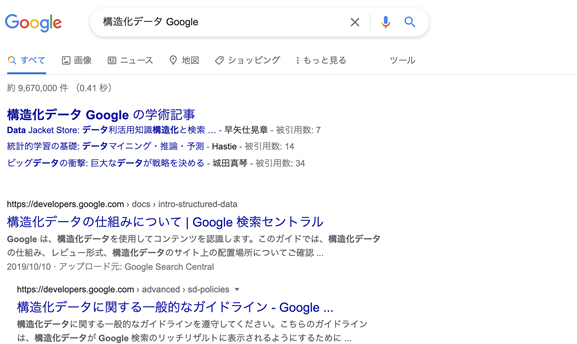
Googleが「構造化データとは何か」を、説明しているところがあります。「構造化データの仕組みについて…」
クリックしましょう。それから、HTMLソースを閲覧しましょう。
header(ヘッダー)内に出てくるのは?

ここまでの短い範囲をご注視ください。これこそ、構造化データを用いるために必要なソースが埋め込まれたパーツです。
スクリプト<script>のタイプについてですが
・<script type="application/ld+json">
と宣言されています。
これはスクリプトの種類が「JSON-LD」と指定されているのです。
このように指定しておくと、(Googleの)システム側で「JSON-LDのプラットフォームを用いて理解すればいいのだ」と判断されるのです。
その他も、コンピュータに対して理解の仕方を説明するパーツでいっぱいです。
・"@context "
・"https//schema.org/ "
これらは、文脈に関する指示ですね。schema.orgというパーツの文脈にもとづいて理解しろと促しているのでしょう。
type(タイプ)についても、
・"@type": Recipe" ,
こう記述しておけば、Googleのシステムは「これはRecipe・レシピなのだ」と理解してくれます。
料理にたとえるなら、ただ単に「小麦粉」「卵」といった何か言葉が書いてある~という理解にとどまらなくなるのです。これはレシピだから料理の作り方だということまでシステムが理解可能になるのです。
その意味では、その次の
・"name ": "Party Coffee Cake "
ここは、レシピの名前がパーティーコーヒーケーキ~だといった説明を行っているわけで、わかりやすいですね。
そして
・"author ": {
「author(オーサー)」という英単語は有名かもしれませんが、著者という意味ですね。誰がつくったのかということです。
・"@type ": "Person "
著者の名前は人だということです。
・"name": "Mary Stone"
},
ここは、メアリー・ストーンという人物がつくったのだという情報をシステムに向けて教え込むことができます。
・datePublished ": "2018-03-10 "
このページが作られた日付ですね。
「datePublished」は、元来は書物等の出版日というニュアンスです。
datePublishedを活用すれば「そのWebページの情報がいつできたのか」も、システムに教え込むことができますね。
付け加えますと、システムに教え込ませる情報は、新しい情報に限ります。古い情報の優先度は自然と低いもの。
いくら構造化データに立派な情報を取り込めたとしても、その情報が古びていったら、Googleは上位に目立つように表示することは……? ないでしょう。
構造化データの本質を語るなら、「古い=悪」。新しさは命。
古い情報は、古いという1点だけでも間違いをはらんでしまいます。この考え方は、構造化データだけにとどまりません。Webすべてに言えることですね。とにかく、新しい情報を発信しないと通用しません。
そのためには? コンスタントな発信が大前提となります。頻繁な発信を、コーポレートサイトでもオフィシャルブログでもYouTubeアカウントでも、発信する。そのような体制を自社内に構築しないといけないのです。さもないと、絶対に競争で敗北します。
・"description ": "This coffee cake is awesome and perfect for party…"
これはいろいろなレシピの内容に関して、です。
「This coffee cake is awesome and perfect for party……」
を訳すなら
「このコーヒーケーキは凄いです。そしてパーティーに完璧です」
と書くのが妥当でしょう。
※なお、このDescriptionのような長文、実はGoogle等のシステムはどこまで理解できるのか判然としていません。 なんといっても長文が書かれますから。
とはいえ、システムの中では「主語が何なのか」「述語が何なのか」「目的語は何なのか」~くらいなら認識できていても不思議ではありません。
・"prep Time ": "PT20M "
これは「プレパレーションタイム」という意味です。準備する時間のことですね。「このコーヒーケーキを準備する時間は、20分くらいです」です、という意味です。
構造化データ、その他の種類に関して
1 構造化データには、まだほかにも種類&使い方があります
先程、レシピの構造化データを紹介しましたが、ネット上でよく見かける構造化データの例といえば「Q&A」や「求人情報」のような種類ではないでしょうか。
そのほかに、覚えておいたほうがよい種類を若干あげてみましょう。「パンくずリスト」の場合、を用います。
たとえば「SEO」という単語で検索したら、このような結果になります。
www.gyro-n.com>SEO>SEOハックコラム▼
ドメイン名があって、ディレクトリ名があって、そして……「SEOハックコラム」という部分もディレクトリ名の一部ではあるのですが、普通でしたらこの部分にURL等が出てくるでしょう。
しかしその代わりに、Webページの制作者・管理者側が「これをこの通りに出してほしい」と、ある程度指定することも可能なのです。
本来なら出てくるURLは「what-is-seo」ですが、この「what-is-seo」を確かめましょうか。
このようにURLがそのまま表示されるのが普通です。
しかし構造化データをコントロールすれば、パンくずリストのURL欄に、指定したパンくずリストの文言を表示できるのです。
たったこれだけのことでも、いくばくかのPRにはなりますからやる価値はあるでしょう。
構造化データの本質を、また別の切り口で語るなら「検索結果上で目立たせて、PR効果を大きく高めること」です。
たとえば、「コンサート 東京」で検索しましょう。すると、出てきたのは?
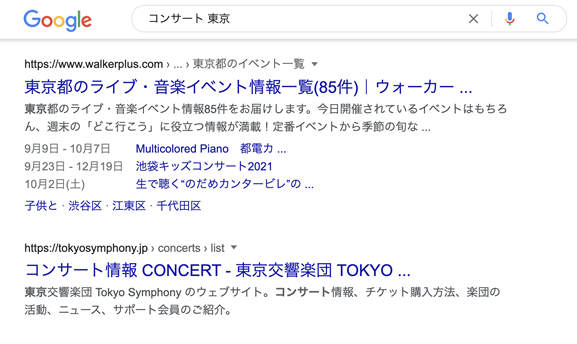
www.walkerplus.com>…>東京都のイベント一覧
※このサイトはポータルサイトのため、施策の内容が細かくて、よい例になりそうです。
6月5日・6月14日 新国立劇場バレエ団「不思議……
6月13日(土) 東京シティ・フィルのドラゴンクエリ
6月20日(土) ミュージカル…
3件まで表示されています。間違いなく、構造化データを実装したことで出た成果です。
2 構造化データを利用できるのは何から何までなのか?
それでは「構造化データを実装したら、どんなテーマのページがどんな見かけになるのか?」この点をもっと詳細に理解するために、構造化データの各種類の説明に移りましょう。
ここで助かるのは、「どのようなHTMLタグを貼り付けたらいいのか」その点を非常に詳細に説明しているページの存在です(Googleの公式サイト内に設置されています)。
このページにアクセスすることは簡単です。「構造化データ 検索結果ギャラリー」で検索しましょう。
「検索ギャラリーを見る」という指示が出てきます。ここで構造化データのサンプルが出てきます。
1.記事

次のように書かれています。
> サムネイルより大きな画像を添えた見出しテキストなど、トップニュース カルーセルやリッチリザルトの機能で表示されるニュース、スポーツ、ブログ記事
カルーセルとはこの場合、内容が右から左へと次々に遷移する表示形式のことです。現在のWebでは広告でおなじみとなっていますね。たとえばFacebookの広告では、さかんに採用されています。
リッチリザルトとは、数種類の画像を表示する手法ですが、ニュース・スポーツ・ブログ記事等でこれまた多用されています。
というわけで構造化データも、これらの技術とともに用いられているのです。たとえばGoogleのカルーセル欄に出す広告を使う際に企業に導入されているのです。
2.書籍
書籍等を描くなどして出版したとき、この書籍の部分を豊かな表示にすることが、構造化データのおかげで可能となりました。

3.パンくずリスト
これは前述していますが、そのページがサイト階層内のどこに位置するのかを説明するテキストを、平易な言葉で表示できます(カラフルにして目立たせることも可能)。日本語の場合は、もちろん日本語で表示されます。
4.カルーセル
これまた、先ほど述べたばかりのため省略させていただきます。
5.コース

> プロバイダ固有のリストに表示される教育コース、プロバイダ、簡単な説明を掲載できます
こう書かれている通りです。
たとえば日本語であれば、「経済学部 京都」で検索すると、どうなるでしょうか? 京都の中にある大学の経済学部の情報が出てくるはずです。
その際に、その経済学部の中にはどんなコースがあるのか(経済○○科ですとか、情報○○科ですとか、になるでしょう)、それらの情報を詳細に商品化できるということになります。
6.よくある質問

これまた、前述していますが、正確な定義は
> 特定のトピックに関する質問と回答の一覧を掲載したページ
とのことです。
7.イメージライセンスメタデータ(β版)
イメージです。画像検索みたいな形で画像を表示して、露出を増やす~というやり方も可能です。
種類の紹介はこれで終わりますが、ほかにも
・評論家レビュー
・データセット
・雇用主の総合評価
~と、幅広いです。
構造化データとSEOの、切っても切れない関係

SEOは、新しい段階を迎えています。
ひと昔前のSEOでは、GoogleやYahoo! JAPANのような大手検索エンジンで上位表示されることが最優先の目標でした。
※最近は、地図検索欄で上位表示するためのMEO(Map Engine Optimization)が追加されていますが……
しかし少し前からSEOでは、オーガニック検索において自社サイトが表示されたときに、ライバル会社のサイトよりも広い広告表示領域をゲットすることも、大きなターゲットとなっています。
それがうまくいけば? そこで細かい情報を多めに掲載できます。「ここは、会社としてしっかりしているらしい」といった一種のブランディングができるチャンスです。
こうしてリンクのクリック率を高めて、自社サイトへの流入を増やすのです。
構造化データを実施しても、それだけでオーガニック検索の結果で優遇される、という保証はありません。
しかしGoogleは、構造化データを実施した各企業のサイトが、どれくらい信用できそうなのか、人気があるのかを計測しているのです。
やはりオーガニック検索の結果は、大きくものをいうのです。上位表示に成功したら構造化データが表示される頻度もがぜん高まるのです。
とにかく、構造化データの実装作業は、自社サイトの実力を高めることと並行して行うべき。実力の向上に成功したサイトに与えられた特権のひとつとして、構造化データが与えられているのだと解釈してもいいくらいです。
構造化データの今後の展開を予測するとしたら?

ここまで構造化データの説明を続けてきましたが、最後にこれからの変化について補足して終わりにしましょう。
それは、遠い先を見据えたGoogleの野望について、です。
たとえば、(これは新しい話でもないのですが)「ゼロクリック」に関する野望をGoogleは長いこと温めてきました。
1 ゼロクリックが粛々と進化しています
「200平米 何坪」といった組み合わせで検索したら、ゼロクリックとは何なのかを見物できます。
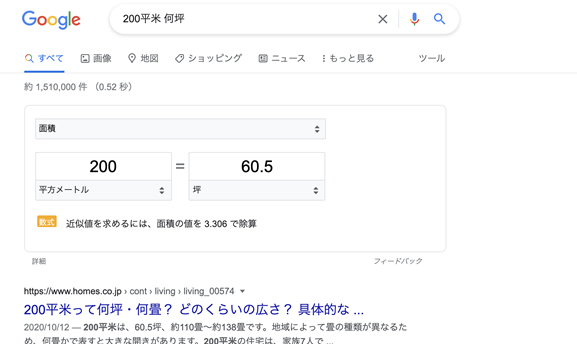
少し前までは、こうした検索を試みると? 「200平米で何坪~」と書かれたページが表示されていたものでした。
今でも表示は変わらず続いていますが……しかし明白に変化した点があります。
それは、各ページの前に「200平方メートル=60.5坪」と、正解をGoogleがユーザに向けて公開してしまっています。
しかもここで、単位を変更した場合の計算結果までできて、至れり尽くせりです。
そして「羽田空港から成田空港までいくら」で検索すると? どうなるでしょうか?
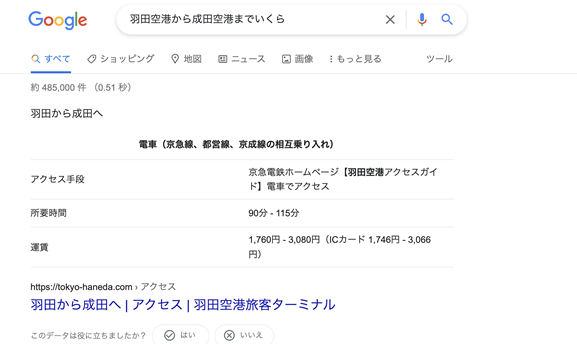
「羽田空港と成田空港の位置と距離:直線距離にすると63㎞です」と、答えをてきぱきと返してしまうのです。
この答えは、Googleの内部システムが計算でもして出しているのでしょうか? そうではありません。
※どうやら、検索フォームの真下に出てくる
「羽田空港~成田空港の移動方法まとめ【2019年度版】!格安旅行」
から情報をコピーしている模様です。強調スニペットで対応しているのです。
強調スニペットとは何でしょうか?
これまでのGoogleは、ユーザが検索するキーワードに合わせて、その答えが説明されているWebページを1位や2位にランクさせていました。
しかし、それの前に極力Googleの検索結果内で答えを返してしまうのです。これが強調スニペットです。
2 なぜゼロクリックがはじまったのか?
Googleの社員の立場になると「よそのWebサイトにユーザという客を送り出したくない」、そういう心情になっても不思議ではないでしょう。
Googleの社員だって毎日あくせく仕事しています。それなのに、ユーザに自社のサービス(Googleの検索エンジン)を無料で使わせておきながら、そのユーザをそのまま他社のサイトに送り出してしまうのでは、何か釈然としないでしょう。
単純な質問・疑問に対する回答なら、
・Google自身で答えを出して情報提供する
・Googleから見ていちばん信頼できる他社(≒検索結果1位の会社のサイト)の答えをコピーして提供してしまう
~の、どちらかを実行したほうが、Googleのエンジン滞在時間が自然と延びることになります。それをGoogleは望んでいる模様です。
どこの会社も、ユーザが自社サイト内に滞在する時間を延ばそうとしています。Googleだって人の子ですから、同じことを希望するようになっても驚きではないでしょう。Googleを責めるわけにはいかないでしょう。
ちなみに、Googleと同様にYahoo!もやっているのです(といっても、完全に同じことばかりではありませんが)。
「エルメス 財布」で検索すると、Yahoo!ショッピングのページが出てきますし、ソフトバンクグループがやっているPayPayの情報が多めに出てきます。もちろんYahoo!知恵袋だって出てきます。
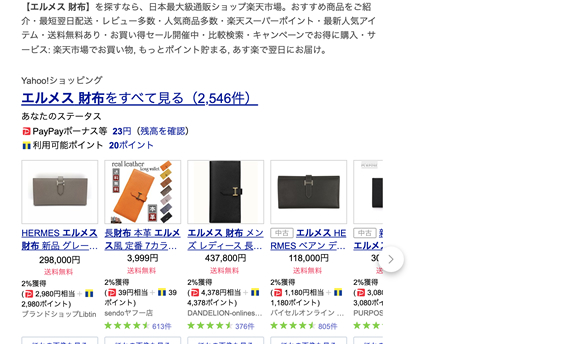
Yahoo!もYahoo!で、自社のプラットフォーム内でユーザが求める情報を完結させたい、そういう思惑があるのです。
これらをGoogleやYahoo!に禁止するのは酷な要求でしょう。
GoogleもYahoo!も公的な存在ではありますが、いわゆる株式会社でもあるのです。自社の利益や株主の利益のために働くことは止められません。
3 ゼロクリックのすさまじい普及は何を意味するのか?
ところで今から少し前、2019年6月に、衝撃的なレポートが発表されました。衝撃を受けたのは一般市民ではありませんが、それでも世界各国のWeb関係者を驚かせたことは間違いありません。
発表したのは、ランド・フィシキン(Rand Fishkin)社長率いるスパークトロという名の会社でした。
Paid,Organic,&Zero-Click Searches in Google(ペイドオーガニックスサーチズイングーグル)というデータです。
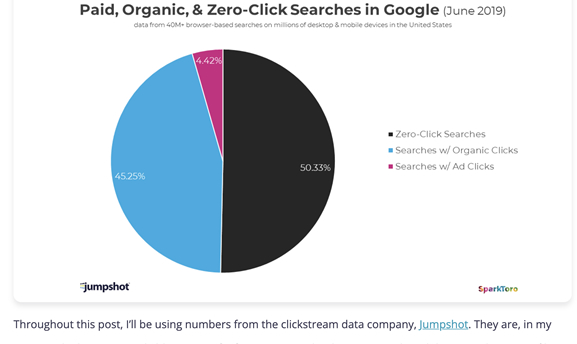
スパークトロ社の調査によると、Googleユーザの50.33%が検索結果からどこもクリックしていなかった、とのことです。先ほどの「200平米=60.5坪」のような情報を調べるだけなら、どこのサイトもクリックしなくてよかったからでしょう。
「羽田空港から成田空港までどれくらいなのか」を知ろうとしたユーザにとっても同じことがいえます。検索したらただちに「63km」と出てくるのなら、その情報の出典である「羽田空港~成田空港の移動方法まとめ【2019年度版】!格安旅行」を見に行く必要は失せてしまいます。
これが、ゼロクリックが巻き起こした一連の現象です。
4 ゼロクリックから読み取るべき、SEOにおける教訓とは
ゼロクリックは、SEOにおける「自社サイトの、終わりなき成長」の大切さを教えてくれます。
それを知りたかったら、「渋谷 美容院」といった、競争の激しいキーワードで検索するだけでじゅうぶんです。
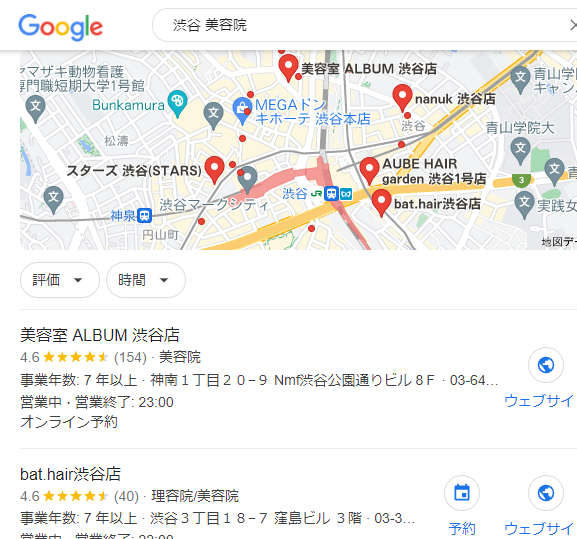
渋谷の美容院もたくさんあることでしょうが、その中で人気のある店がまとめて出てきます。レビューを見ると40件ですとか154件ですとか、大量に書き込まれていて人気の高さがうかがえます。
これもゼロクリックの効果のひとつです。ネットユーザからすると、このようなGoogleのレビューだけで事足りてしまうのです。それぞれの美容院の公式サイトへ行かなくてよいわけです。
それにGoogleが、その店への道案内もしてくれます。おまけに電話番号だって出てきます……それどころか、その場で電話発信ボタンまで出てきます。
こうして、よそのサイトを見に行く需要は、明らかに削がれているのです。これがゼロクリックの恐ろしさです。
※ただ、世の中にはずっと昔から独占禁止法が存在します。日本ではこの手の法令の威力はあまり身近ではないかもしれません。しかし、北米やEUでは強いです。独占と疑われることがあればささいなことでも、何千億円~何兆円という規模の罰金が科されます。
というわけでGoogleも、ゼロクリックはびくびくしながら進めている疑いがあるのですが……そのいっぽうで、Googleしか提供できないような独自性のあるサービスであれば、許容されるチャンスが増えてしまうのです。
たとえば、地図会社で有名なところが無数にあるなら、Googleマップだけを表示する必要性はありませんね。しかし世界の趨勢は、「Googleマップは地図として最高」という認識でいっぱいです。
こうなると、うるさいEU政府の高官もなかなか文句をいえなくなるのです。
というわけで、今から数年後、また統計すると、ゼロクリックのシェアはもっと上がっているかもしれません。70~80%にまで跳ね上がっているかもしれません。
したがって、Webサイト運営者がだらしないと行き詰まります! サイトにアクセスしない限り手に入らないような貴重な情報をいつまでも発信していかないと、ゼロクリックにユーザおよび顧客を奪われてしまう恐れが濃厚なのです。そもそもSEOを続ける意義もなくなりかねません。
大げさに聞こえるかもしれませんが、危機意識を持つことは忘れてはいけません。
まとめ:構造化データはSEOの在り方&計画の立て方に関して、あれこれと大切なことを考えさせてくれます
構造化データはSEOばかりでなく、自社サイトの長期的な戦略の方向性に関してヒントを与えてくれます。
- 検索結果が表示される際に、数行くらい余分な結果を出すことができる……それが構造化データを実装したときの利益。
- 構造化データを実装すると、ネットユーザにとって欲しい情報が掲載されているページがどこなのかわかって便利。カスタマージャーニーの提供にもつながる。
- 構造化データが表示されるように変われば、他の競合するサイトと比べて、目立てる。それに加えて、うまくいけばGoogleからの評価が高まるという二次的なメリットもある。
- 構造化データをシステムが理解するようになって、生まれたのは「そのときどきに、世界中の不特定多数のネットユーザが検索したクエリに最適だと判断しうるデータを、抽出して表示する」という現象。
- 構造化データの規格は数種類あるが、いちばんニーズがあるのは「JSON-LD」。HTMLのヘッダーに記述する必要があるが、難しい作業ではない。
- 現在のGoogleは、ゼロクリックの機能の拡大に努力しているが……、この結果、サイト内でのコンテンツの重要性を高めることが改めて大切になっていく。









