HOME > アルゴリズムアップデート
アルゴリズムアップデート
Googleはコンテンツがオリジナルのものかをどのように判定しているのか?
2024年09月29日

Googleは、オリジナルコンテンツを提供しているサイトを高く評価するといわれています。しかし、ここで1つの疑問が浮かびます。それは、Googleがどのようにしてコンテンツのオリジナリティを判断しているのかという点です。膨大な量のコンテンツがインターネット上に存在する中で、Googleはどのような基準や技術を使って、どのコンテンツがオリジナルかを評価しているのでしょうか?
1. フィンガープリンティング技術とは?
フィンガープリンティング技術は、データの「指紋」を作成して、それを使って他のデータと比較する方法です。たとえば、あなたが作成したブログ記事が他のどのコンテンツとも違うかどうかを、データの特徴を「指紋」として捉え、それを比べることで確認します。
《参考サイト》 主成分分析による混合データ・フィンガープリンティング
具体的には、主成分分析 (PCA) という技術を使って、大量のデータの中から重要な部分を抽出し、その特徴を圧縮してフィンガープリント(指紋)に変換します。これにより、データの類似性を少ない計算で確認できるため、大量のデータがあっても効率よく独自性を評価することができます。特に、データが不正に流出した場合に、流出したデータを元のデータセットと比較して出所を特定するのにも使われます。
例えば、あなたの記事が「SEO対策」についてだとします。Googleは、その記事の中から重要なキーワードや文のパターンを抽出し、それを「指紋」としてデータベースに保存します。これにより、他のサイトに似たような内容の記事がないかを簡単にチェックできるのです。
さらに、ここで使われる技術が主成分分析(PCA)です。PCAは、膨大なデータの中から一番重要な特徴を取り出して、その情報を圧縮します。たとえば、あなたの記事の100個の要素(キーワード、文の構造、テーマなど)から、特に重要な数個の要素だけを取り出し、それを「指紋」にします。
この指紋を使って、Googleは他のサイトにある類似した記事と比べ、あなたのコンテンツがどれだけオリジナルかを確認します。特に、データが不正に流出した場合に、このフィンガープリンティング技術を使って、流出したデータが元々どのデータセットから出たものなのかを特定するのにも役立ちます。
このように、フィンガープリンティング技術は、コンテンツの独自性や類似性を効率的に評価するために重要な役割を果たしています。
2. 主成分分析 (PCA) とは?
主成分分析は、複雑なデータから重要な特徴だけを取り出すための技術です。多くのデータには多様な情報が含まれていますが、そのすべてを評価するのは大変です。そこで、PCAを使うことで、データの本質的な部分だけを取り出して、理解しやすくします。
たとえば、100個の変数があるデータから、そのうちのいくつかが重要な変動要因だと分かった場合、それらを使ってデータをシンプルに表現できます。こうしてコンテンツの独自性やパフォーマンスを効率よく分析できるようになります。
具体的な例として、顧客満足度調査を考えてみましょう。仮に、あなたが100人の顧客にアンケートを取り、その結果には100個の質問(変数)が含まれているとします。しかし、すべての質問を個別に分析すると、どの質問が顧客満足に一番影響しているのか分かりにくいですよね。そこでPCAを使うと、これら100個の質問の中から、特に重要な質問、たとえば「製品の品質」「カスタマーサポート」「価格」の3つが満足度に大きく影響していることが分かります。
このように、PCAは100個の情報から3つの主要な要因にデータを圧縮し、顧客満足度を効率よく理解できるようにします。少ない情報でデータの全体像を捉えることができ、ビジネスの意思決定を迅速に行う際にも役立ちます。
つまり、PCAはデータを簡潔にまとめ、その本質的な特徴を掴むために非常に強力なツールなのです。
3. 時系列分析
コンテンツのオリジナリティを判断する際に、そのコンテンツがいつ最初に公開されたかという時期も重要です。Googleは、コンテンツが最初にインデックスされたタイミングを把握しており、その情報を元に、どれがオリジナルかを判断します。
たとえば、同じ内容のコンテンツが2つあった場合、最初に公開された方がオリジナルと見なされ、検索結果でも優先される可能性があります。
具体的な例として、同じ内容の記事が2つのブログに掲載された場合を考えてみましょう。
たとえば、Aさんが「2024年最新SEOテクニック」という記事を1月1日に公開し、Bさんが同じ内容の記事を1月5日に公開したとします。この場合、GoogleはAさんの記事を先にインデックスし、その公開日時を記録しています。そのため、GoogleはAさんの記事をオリジナルと見なし、検索結果でもAさんの記事を優先して表示する可能性が高いです。
一方、Bさんの記事は、公開された日時がAさんの記事より遅いため、オリジナルとして評価されない可能性があります。つまり、コンテンツがどれだけ早く公開されたかが、そのコンテンツがオリジナルかどうかを判断する重要な要素になります。
このように、時系列分析は、同じ内容のコンテンツが複数存在する場合に、どれが最初に公開されたかをもとにオリジナリティを評価し、検索順位に影響を与える重要な役割を果たしています。
4. 機械学習アルゴリズムによる独自性の評価
Googleは、AIや機械学習技術を使って、大量のデータを分析し、コンテンツの独自性を判断しています。AIがコンテンツのパターンや傾向を学習することで、似ている記事やまったく新しい内容のものを見分けることができます。
具体的な例として、AIがニュース記事を評価する場合を考えてみましょう。たとえば、同じニューストピックに関する記事が、複数のウェブサイトに掲載されたとします。それぞれの記事は同じテーマを扱っていても、記事の書き方や視点、使用されているキーワードが異なる場合があります。ここで、GoogleのAIは機械学習を通じて、各記事の構造や言葉の使い方、全体的なトーンを分析し、どの記事が他のものと似ているか、あるいはどれが独自の視点を持っているかを見極めます。
例えば、Aサイトの記事が他のニュースサイトの記事とほぼ同じ内容だった場合、AIはその記事をオリジナルではなくコピーと判断する可能性が高くなります。一方、Bサイトが同じニューストピックに対して新しい視点や独自のデータを使って記事を書いた場合、AIはBサイトの記事をより独自性が高いと評価します。
このように、機械学習アルゴリズムは、単に同じトピックを扱っているだけでなく、コンテンツの書き方やデータの使い方など、より深い部分での違いを学習して判断します。その結果、Googleはオリジナリティの高い記事を見つけ出し、検索結果でも優先して表示することができるのです。
この技術により、AIは大量のコンテンツを効率よく分析し、どの記事が本当にユニークで、価値があるかを精確に判断できるようになっています。
具体的なアルゴリズムの詳細は公開されていませんが、Googleがこうした技術を駆使して、検索結果に表示されるコンテンツの質を高めていることは間違いありません。
まとめ
これらの技術を活用することで、Googleは検索結果に表示されるコンテンツの独自性や質を正確に評価しています。オリジナルで高品質なコンテンツを作成することが、SEOにおいて非常に重要であり、あなたのコンテンツが他のものと差別化されるためのカギとなります。こうした評価基準を意識してコンテンツ制作をすれば検索で上位表示される記事が作成できるようになるはずです。
Googleはサイト滞在時間を見ていた!サイト滞在時間が長いと検索で上位表示しやすくなる
2024年07月16日

Googleは検索結果ページからリンクされているサイトにユーザーが遷移した後のサイト滞在時間を測定しているのか?これは長年にわたって世界のSEOプロフェッショナルの中で論争を呼んでいた疑問です。Googleは公式に「サイト滞在時間は見ていない」と発言していましたが、最近になってこの論争に終止符が打たれました。
サイト滞在時間とは?
サイト滞在時間とは、サイト訪問者がサイトに滞在した平均時間のことを いいます。 サイト滞在時間が長ければそれだけそのサイトに価値のある情報が多い はずだという理論で、サイト滞在時間が長いサイトのほうが短いサイトよりも人気があるとGoogleが判断してサイトの評価が高まると一般的に信じられています。Googleは特に公式にサイト滞在時間が長ければ長いほどサイトの評価が高くなるとは公表していません。
しかし、Googleが何らかの形でサイト滞在時間のデータを収集して、検索順位を決める際に利用しているのではないかと思わせる重要な情報が2つあります。
1つ目の情報は、「暗黙のユーザーフィードバックに基づく検索結果の順位の変更」(US10229166B1)というGoogleが取得した特許情報です。
《US10229166B1の特許情報》

この特許によれば、Googleはユーザーの行動を詳細に分析し、ページの人気度を評価しているということです。
その方法は、検索結果ページに表示されている各サイトへのリンクをクリックしたユーザーが何秒間で戻ってくるかを記録するという方法です。この時間の計測に基づいて、クリックを以下の4つのカテゴリーに分類しているということです。
(1)ショートクリック
ショートクリックは、ユーザーがリンクをクリックして短時間で検索結果ページに戻ってくるクリックです。短い滞在時間(例:10秒)は、ユーザーがページの内容に満足しなかったことを示唆します。例えば、ユーザーが期待した情報が見つからなかったり、ページの内容が魅力的でなかったりする場合です。ショートクリックが多いページには低いスコアが与えられ、検索順位も低くなります。
(2)ミディアムクリック
ミディアムクリックは、滞在時間が短くもなく長くもなく、その中間の時間(例:50秒)です。ユーザーが一定の興味を示してページを閲覧したことを示しており、ショートクリックよりも高いスコアが与えられますが、ロングクリックほどではありません。
(3)ロングクリック
ロングクリックは、ユーザーがリンクをクリックしてから検索結果ページに戻ってくるまでの時間が長いクリック(例:3分)です。ユーザーがページの内容に非常に満足し、詳細に閲覧したことを示します。このため、ロングクリックが多いページには高いスコアが与えられ、検索順位も高くなります。
(4)ラストクリック
ラストクリックは、ユーザーが検索結果ページに戻らないクリックです。これは、ユーザーがそのページに完全に満足し、他の検索結果を見る必要がないと感じたことを示します。ラストクリックが多いページには、最高のスコアが与えられます。
《4つの種類のクリックの概念図》

Googleは、これらのクリックの種類と推定サイト滞在時間を用いて、どのページがユーザーに気に入られたか、気に入られなかったかを推測していると考えられます。ショートクリックが多いページは検索順位が下がり、ロングクリックやラストクリックが多いページは検索順位が上がる仕組みです。これにより、ユーザーにとって有益なページが上位に表示されるようになるため非常に公平で合理的な評価方式だと言えます。ただし、Googleがこうした内容の特許を登録しているかといって実際に検索順位を決める際に使っているということにはなりません。
《関連情報》 サイト滞在時間を伸ばし検索順位を上げる方法は?
Googleの検索アルゴリズム漏洩事件
しかし、Googleがサイト滞在時間を測定し、そのデータを検索順位を決める際に実際に使っている、または使っていたということを示す事件が起きました。
Googleが何らかの形でサイト滞在時間のデータを収集して、検索順位を決める際に利用しているのではないかと思わせる2つ目の情報です。それは、2024年5月に複数のニュースメディアで報道されたGoogleの検索アルゴリズム漏洩事件です。
漏洩した文書の中には「goodClicks」、「badClicks」、「lastLongestClicks」、「unsquashedClicks」など多種多様なクリックデータが収集されていることが明らかになりました。これはまさに、ショートクリック、ミドルクリック、ロングクリック、ラストクリックと同じような概念です。この文書には他にも、Googleが検索結果上のクリック率を順位算定に使っているということや、Googleが無償で配布しているChromeブラウザを使っているユーザーがどのようなサイトのどのようなページを見ているかというデータまで収集していことなど、これまでGoogleが公式に否定して事が事実であったことが裏付けられるものが多数ありました。

このようにGoogleは私達が想像する以上にコンテンツの人気度を精緻なアルゴリズムとデータ収集体制を敷いて評価しています。
サイト滞在時間を伸ばすためにはわかりやすい情報を十分な量だけサイト内の各ページに掲載することが必要です。そして、検索ユーザーが検索結果ページ上にあるリンクをクリックして訪問したランディングページから関連性の高いページにわかりやすくリンクを張ることが必要になります。
まとめ
サイト滞在時間が長いと、ユーザーがそのサイトの内容に満足していることを示し、結果として検索順位が向上する可能性が高まります。Googleは公式にサイト滞在時間を検索順位に反映しているとは公表していませんが、特許情報や最近の検索アルゴリズム漏洩事件から、サイト滞在時間が間接的に評価に影響を与えていることが示唆されています。コンテンツの質を向上させ、訪問者がサイトに長く滞在する工夫をすることで、検索順位の向上を目指しましょう。
【重要】Googleが大型のコアアップデートとスパムアップデートを同時に実施!
2024年03月08日

Googleは2024年3月5日に「March 2024 core update」と呼ばれる新しいコアアップデートと、新しいスパムポリシーを発表しました。このアップデートは、クリック数を稼ぐことだけを目的としたコンテンツを検索結果から減らし、ユーザーにとって実際に有用なコンテンツをより多く表示させることを目的としたものです。また、Googleの検索結果に悪影響を及ぼす可能性のある行為に厳しく対処するために、新しいスパムポリシー(不正行為に対する方針)も導入されました。
今回実施されたコアアップデートの概要
この公式発表によると、今回実施されたコアアップデートは通常のコアアップデートよりも複雑で、複数のコアシステムに変更が加えられたということです。これはGoogleがサイト上のコンテンツの有益さを判定する方法を進化させたということを意味します。
コアシステムとは正式には「コアランキングシステム」と呼ばれるもので、Googleが2022年11月21日に「Google 検索ランキング システムのご紹介」というページで公開した、それまでベールに包まれていたGoogle検索のランキングシステムを説明した検索順位を決める仕組みのことです。
《コアランキングシステムの概念図》
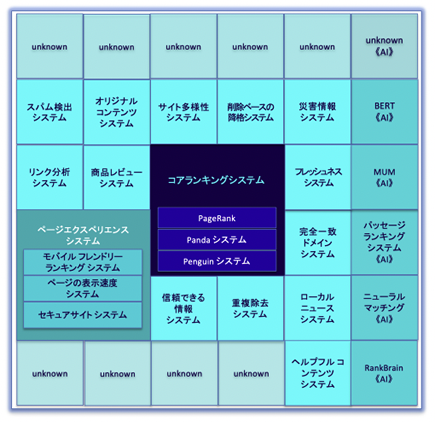
新たに導入されたさまざまな革新的なシグナルと評価方法を用いて、検索ユーザーにとってより有益な検索結果を表示するようにコアランキングシステムを強化したということです。アップデートの完全な展開には最大で1か月かかる可能性があり、ランキングの変動が通常のコアアップデート時よりも多くなるということが発表されました。
今回発表された新しいスパムアップデートについて
今回のコアアップデートの実施と同時に発表された、Googleの新しいスパムポリシーは、Googleの検索結果の質に悪影響を与える可能性のある実践に対応するために決められたものです。具体的には、期限切れドメインの乱用、大量コンテンツの乱用、サイト評判の乱用に対する3つの新ポリシーが導入されています。これらのポリシーに違反するサイトは、今回のスパムアップデートの実施により検索結果でのランキングが下がるか、全く表示されなくなる可能性があります。
期限切れドメインの乱用
そのスパムアップデートの内容の1つは期限切れドメインの乱用に対するペナルティーです。期限切れドメインの乱用とは、他者が以前使った後に手放した期限切れのドメイン名を検索ランキングを操作する目的で購入し、ユーザーにとってほとんどまたは全く価値のないサイトを運営することを指します。これはいわゆるオールドドメインと呼ばれる古いドメインを自社サイトに紐づけて自社サイトが新しいサイトなのに古いサイトになりすますという手法です。

大量コンテンツの乱用
ユーザーに役立つことなく検索ランキングを操作する主な目的で多数のページを生成する行為です。ユーザーにとってほとんど意味の無いページを作ってもSEOにはプラスにならなくなりました。ページを作る目的は必ずユーザーの何らかの課題を解決するというものでなくてはなりません。

サイトの評判を乱用すること
第三者のページがサイトの主な目的とは独立して、または第一者(サイトとそのドメイン名の所有者)の密接な監督や関与なしに公開され、検索ランキングを操作する目的で利用される場合を指します。これはいわゆる信頼性が高いとGoogleから評価されている自社のドメインの一部を他人に貸し出すという不正テクニックで「寄生サイト」だとか、「ドメイン貸し」と言われるブラックハットのSEOテクニックのことです。このような非常にずる賢い手法もこのスパムアップデートにより完全に無効化になった可能性があります。本当に無効化されたのかは今後情報を収集してこのブログでも報告させていただきます。
これらの対策を実施することで、Googleのスパムポリシーに違反することなく、ユーザーにとって有益なサイトを運営することが可能になります。常にユーザー第一の方針を貫き、高品質なコンテンツの提供に努めることがGoogleの検索結果での成功につながります。
《関連情報》 サイトの品質改善と改善効果が出るまでの時間
以上ですが今回の大型コアアップデートの詳細に関しては未だ実施されたばかりなので情報が入ってきておりませんが、こちらのほうも分かり次第このブログでレポートさせていただきます。
鈴木将司の最新作品


プロフィール

フォローしてSEOを学ぼう!
| 2026年 03月 >> | ||||||
|---|---|---|---|---|---|---|
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
最新記事
- AIモード時代、「英会話 大阪」はスクール検索ではなく学習設計の入口になる
- 「スマートフォンケース 通販」でSEOには出るのに、AIモードではうちのブランドが出てこない
- 「群馬県で相続問題に強い弁護士」とAIモードで検索すると、弁護士の一覧ではなく、相続問題を解決するための最初の道筋が示された
- 「軽井沢 カフェ 人気」をAIモードで検索すると、なぜ「お店一覧」ではなく「過ごし方」が返ってくるのか
- 「高級家具 通販」はAIモードで「ショップ比較」ではなく「価値観別の買い方」として回答されている
- SEOにおける「共感」の設計 - なぜ「正しい情報」より「わかってもらえた感」が強いのか
- 検索意図の読み解き方 - キーワードの裏にある「感情」と「状況」をどう捉えるか
- 「動物病院 求人」はAIモードで「求人探し」ではなく「キャリア設計の入口」として提示されている
- SEOで「ストーリーテリング」が重要な理由 - 検索エンジンと人の記憶に残るコンテンツの正体
- 「新宿 焼き肉」でAIモードで検索した回答結果は「店探し」ではなく「シーン別の最適解」として回答されている
アーカイブ
- 2026年03月
- 2026年02月
- 2026年01月
- 2025年12月
- 2025年11月
- 2025年10月
- 2025年09月
- 2025年04月
- 2025年02月
- 2025年01月
- 2024年12月
- 2024年11月
- 2024年10月
- 2024年09月
- 2024年08月
- 2024年07月
- 2024年06月
- 2024年05月
- 2024年04月
- 2024年03月
- 2024年02月
- 2024年01月
- 2022年06月
- 2022年04月
- 2022年03月
- 2022年01月
- 2021年12月
- 2021年11月
- 2021年09月
- 2021年08月
- 2021年07月
- 2021年06月
- 2021年04月
- 2020年12月
- 2020年11月
- 2020年09月
- 2020年08月
- 2020年07月
- 2020年06月
- 2020年05月
- 2020年03月
- 2020年02月
- 2019年12月
- 2019年11月
- 2019年10月
- 2019年09月
- 2019年08月
- 2019年07月
- 2019年06月
- 2019年05月
- 2019年04月
- 2019年03月
- 2019年02月
- 2019年01月
- 2018年12月
- 2018年11月
- 2018年10月
- 2018年09月
- 2018年08月
- 2018年07月
- 2018年06月
- 2018年05月
- 2018年04月
- 2018年03月
- 2018年02月
- 2018年01月
- 2017年12月
- 2017年11月
- 2017年10月
- 2017年09月
- 2017年08月
- 2017年07月
- 2017年06月
- 2017年05月
- 2017年04月
- 2017年03月
- 2017年02月
- 2017年01月
- 2016年12月
- 2016年11月
- 2016年10月
- 2016年09月
- 2016年08月
- 2016年07月
- 2016年06月
- 2016年05月
- 2016年04月
- 2016年03月
- 2016年02月
- 2016年01月
- 2015年12月
- 2015年11月
- 2015年10月
- 2015年09月
- 2015年08月
- 2015年07月
- 2015年06月
- 2015年05月
- 2015年04月
- 2015年03月
- 2015年02月
- 2015年01月
カテゴリー
- パンダアップデート(20)
- ペンギンアップデート(5)
- スマートフォン集客・モバイルSEO(42)
- Google検索順位変動(5)
- Youtube動画マーケティング(8)
- コンテンツマーケティング(13)
- Web業界の動向(22)
- デジタルマーケティング(14)
- SNSマーケティング(11)
- 成約率アップ(8)
- SEOセミナー(4)
- 認定SEOコンサルタント養成スクール(2)
- 上位表示のヒント(168)
- ビジネスモデル開発(5)
- Bing上位表示対策(1)
- SEOツール(16)
- ヴェニスアップデート(1)
- スマートフォンSEO対策(19)
- アップルの動向(3)
- 人材問題(4)
- Googleの動向(20)
- AI活用とAEO・AIO(73)
- ローカルSEOとGoogleビジネスプロフィール(20)
- ドメイン名とSEO(7)
- アルゴリズムアップデート(45)
- Webの規制問題(8)
リンク集
